
مهمترین الگوریتم های یادگیری ماشین که باید بشناسید
در الگوریتم های یادگیری ماشین، یک قضیه به نام «هیچ نهار رایگانی وجود ندارد» یا No Free Lunch هست که بیان میکند هیچ کدام از الگوریتم های یادگیری ماشین نقش یک میانبر را، که همه کارها را بدون صرف انرژی اضافه برای شما سامان دهد، ندارند. به عبارت دیگر، شما باید هزینه هر تصمیمگیری را بدهید. برای مثال، نمیتوان گفت که شبکههای عصبی همیشه بهتر از درختهای تصمیم هستند یا برعکس. عوامل زیادی مانند اندازه و ساختار مجموعه داده در بهتر عملکردن هر کدام از آنها نسبت به دیگری نقش دارد.
در نتیجه، شما باید انواع الگوریتمهای مختلف را برای مشکل خود امتحان کنید. البته، الگوریتمهایی که امتحان میکنید باید برای مشکل شما مناسب باشند. اگر بخواهیم با یک مثال تناسب الگوریتم با مشکل را نشان دهیم، میتوانیم مثال ابزار لازم برای تمیزکردن خانه را بزنیم. اگر نیاز به تمیزکردن خانه خود داشته باشید، احتمالا از جاروبرقی، جارو دستی یا جارو نپتون استفاده میکنید، اما هیچ وقت برای تمیزکردن خانه از بیل استفاده نمیکنید. انتخاب الگوریتم های یادگیری ماشین هم همینطور است.
ما در اینجا برخی از رایجترین الگوریتم های یادگیری ماشین را معرفی میکنیم.
رایجترین الگوریتم های یادگیری ماشین
انواع رایج الگوریتمها که برای یادگیری ماشین استفاده میشوند شامل موارد زیر هستند:
● رگرسیون خطی (Linear Regression)
● رگرسیون لجستیک (Logistic Regression)
● آنالیز تشخیصی خطی (Linear Discriminant Analysis)
● درخت طبقه بندی و رگرسیون (Classification and Regression Trees)
● بیز نیتیو (Naive Bayes)
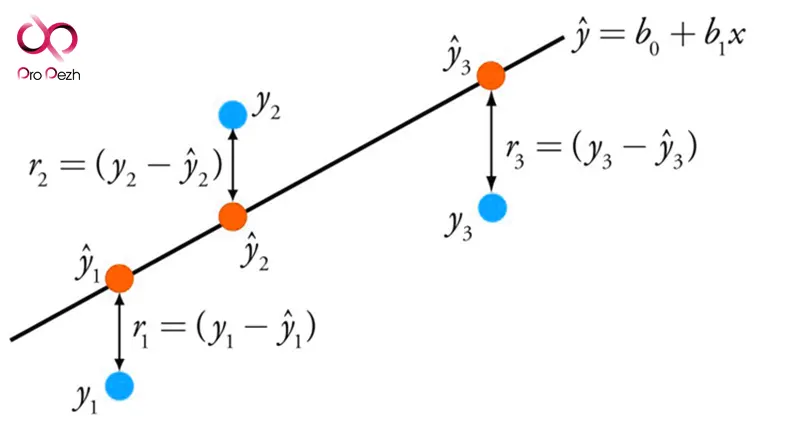
رگرسیون خطی (Linear Regression)
رگرسیون خطی یکی از شناختهشدهترین الگوریتمها در آمار و یادگیری ماشین است. نمایش رگرسیون خطی معادلهای است که خطی را توصیف میکند که بهترین تناسب را با رابطه بین متغیرهای ورودی (x) و متغیرهای خروجی (y)، با یافتن وزنهای خاص برای متغیرهای ورودی به نام ضرایب (B) دارد.تکنیکهای مختلفی را میتوان برای یادگیری مدل رگرسیون خطی از دادهها استفاده کرد، مانند راهحل جبر خطی برای حداقل مربعات معمولی و بهینهسازی نزول گرادیان (gradient descent optimization).
رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک یکی دیگر از الگوریتم های یادگیری ماشین است که از حوزه آمار وام گرفته شده است. این روش برای مسائل طبقهبندی باینری (مشکلات با دو class values) استفاده میشود.
هدف رگرسیون لجستیک مانند رگرسیون خطی یافتن مقادیر ضرایبی است که هر متغیر ورودی را وزن میکند. اما برخلاف رگرسیون خطی، پیشبینی خروجی با استفاده از یک تابع غیرخطی به نام تابع لجستیک است.همانند رگرسیون خطی، رگرسیون لجستیک زمانی بهتر عمل میکند که ویژگیهایی را که با متغیر خروجی مرتبط نیستند و همچنین، ویژگیهایی که بسیار شبیه (همبسته) به یکدیگر هستند را حذف نمایید.
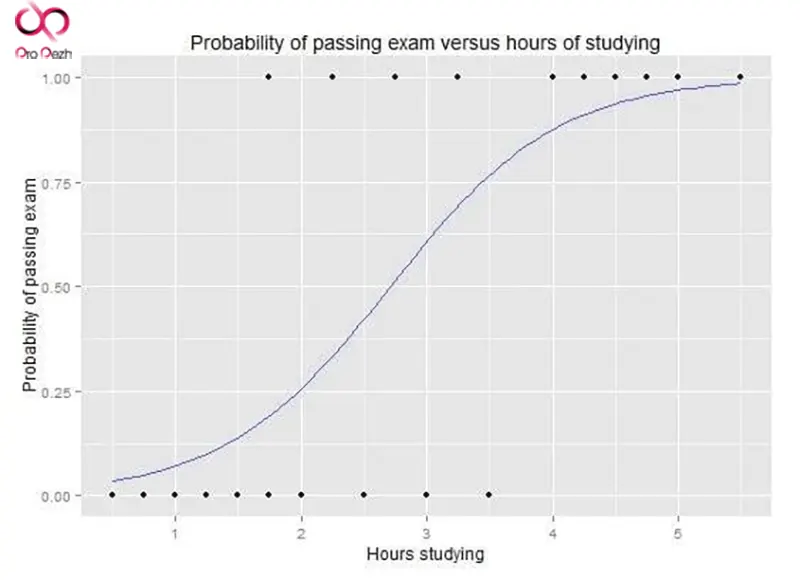
نمودار منحنی رگرسیون لجستیک که احتمال قبولی در امتحان را در مقابل ساعات مطالعه نشان میدهد.
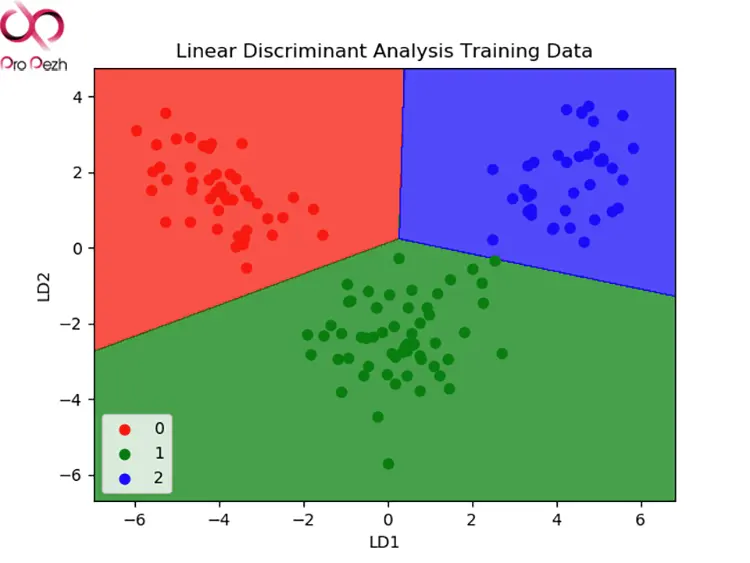
آنالیز تشخیصی خطی (Linear Discriminant Analysis)
رگرسیون لجستیک یک الگوریتم طبقهبندی است که بهطور سنتی فقط به مسائل طبقهبندی دو کلاسه محدود میشود. اگر بیش از دو کلاس دارید، الگوریتم آنالیز تشخیصی خطی، روش طبقهبندی ترجیحی است.
اجرای LDA بسیار ساده است و شامل ویژگیهای آماری دادههای شما است که برای هر کلاس محاسبه میشود. LDA برای یک متغیر ورودی واحد شامل موارد زیر است:
● مقدار میانگین برای هر کلاس
● واریانس در تمام کلاسها
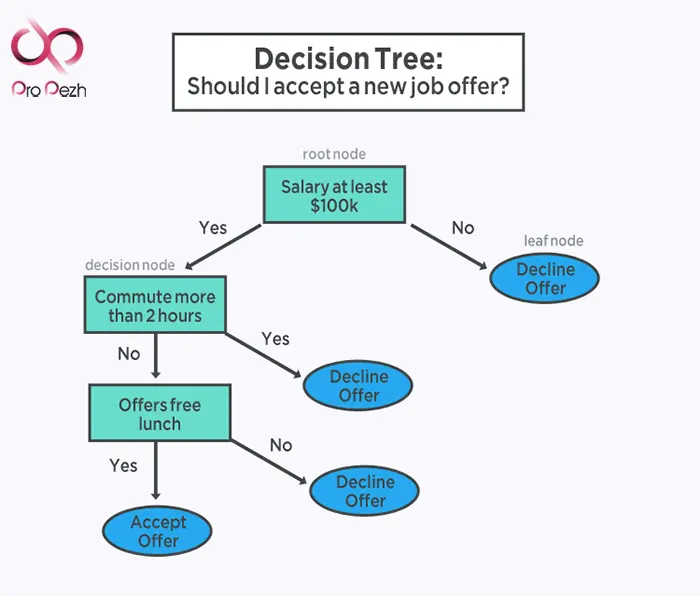
درخت طبقه بندی و رگرسیون (Classification and Regression Trees)
درخت طبقهبندی یا تصمیمگیری یکی از انواع الگوریتمهای یادگیری ماشین است که برای مدلسازی پیشبینی بسیار ضروری است.
نمایش مدل درخت، بهشکل یک درخت باینری است. این درخت باینری از الگوریتمها و ساختارهای داده ساخته میشود. هر گره یاnode نشاندهنده یک متغیر ورودی واحد (x) و یک نقطه تقسیم روی آن متغیر است (با فرض اینکه متغیر عددی است).
گرههای برگ (leaf node) حاوی یک متغیر خروجی (y) هستند که برای پیشبینی استفاده میشوند.
درختان تصمیمگیری، سریع یاد میگیرند و بسیار سریع پیشبینی میکنند. آنها اغلب برای طیف گستردهای از مشکلات، دقیق هستند.
بیز نیتیو (Naive Bayes)
Naive Bayes یا «بیز ساده لوح» یک الگوریتم ساده اما شگفتآور و قدرتمند برای مدلسازی پیشبینی است. این مدل از انواع الگوریتم های یادگیری ماشین، از دو نوع احتمال تشکیلشده است که میتوانند مستقیماً از دادههای آموزشی شما محاسبه شوند:
1) احتمال هر کلاس
2) احتمال شرطی برای هر کلاس با توجه به هر مقدار x.
پس از محاسبه، میتوان از مدل احتمال برای پیشبینی دادههای جدید با استفاده از قضیه بیز استفاده کرد.
Naive Bayes «ساده لوح» نامیده میشود زیرا فرض میکند که هر متغیر ورودی مستقل است. این یک فرض قوی و غیرواقعی برای دادههای واقعی است. با این وجود، این تکنیک در طیف وسیعی از مسائل پیچیده بسیار موثر است.
انواعی از الگوریتمها که توضیح داده شدند، اولین الگوریتم های یادگیری ماشین هستند که هر تازهکاری باید بیاموزد. با این حال، علاوه بر موارد توضیح دادهشده، الگوریتمهای زیر هم در یادگیری ماشین بهشکل رایج استفاده میشوند.
● K-Nearest Neighbors (KNN)
● کوانتیزاسیون برداری یادگیری (LVQ)
● Support Vector Machines (SVM)
● جنگل تصادفی (Random Forest)
● افزایش (Boosting)
● AdaBoost
سخن آخر
الگوریتم های یادگیری ماشین انواع مختلفی دارند که انتخاب آنها باید با توجه به نوع مشکل انجام شود. با این حال، یک الگوریتم خاص یک راه حل منحصر به فرد برای هیچ مشکلی محسوب نمیشود.لذا دانستن تمامی این الگوریتم ها به شما کمک میکند که در موقعیت های مختلف به چه شکل و از کدام یک استفاده کنید.
میتوانید با شرکت در دوره یادگیری ماشین پروپژ، نسبت به این موارد بیشتر آگاه شویذ.
منبع :https://builtin.com/data-science/tour-top-10-algorithms-machine-learning-newbies
مطالب زیر را حتما مطالعه کنید

انواع مدل های یادگیری ماشین
یادگیری ماشین (machine learning ) چیست؟ ماشین لرنینگ
دوره های آموزشی مرتبط



1 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
الگوریتم های یادگیری ماشین رو به خوبی شرح دادید. سپاس